There are two main types of PDF documents – those that are created electronically using PDF creation software and those that are created from a scanner or other photo-imaging equipment. PDF creation software actually builds a PDF document that has an internal structure, denoting characters, fonts and position – although the raw information makes little sense to the human eye. A scanned PDF is basically just a flat image of a document – hence, scanning a page of text results in a picture of words being represented on the screen. In order to take information from this sort of scanned PDF, OCR technology is required so that each character can be optically recognized and then represented.
You can generally visually determine if a document is a scanned document by enlarging the picture on your screen and looking closely at the text. A scanned image will appear to have much poorer resolution, when looked at closely, than electronically created PDF document.
However, if you are still unsure whether your PDF file is scanned or native (electronic), you can just open the file in Able2Extract. Then left click with your mouse on the file and drag the mouse pointer over certain area (as if you are trying to select a portion of the data).
If the whole selected area becomes highlighted (blue) – not line by line, but as a solid blue rectangle – it means that the file is scanned. Hence, you will need Professional edition of our application, as only Professional edition contains the OCR engine required to convert scanned PDFs.
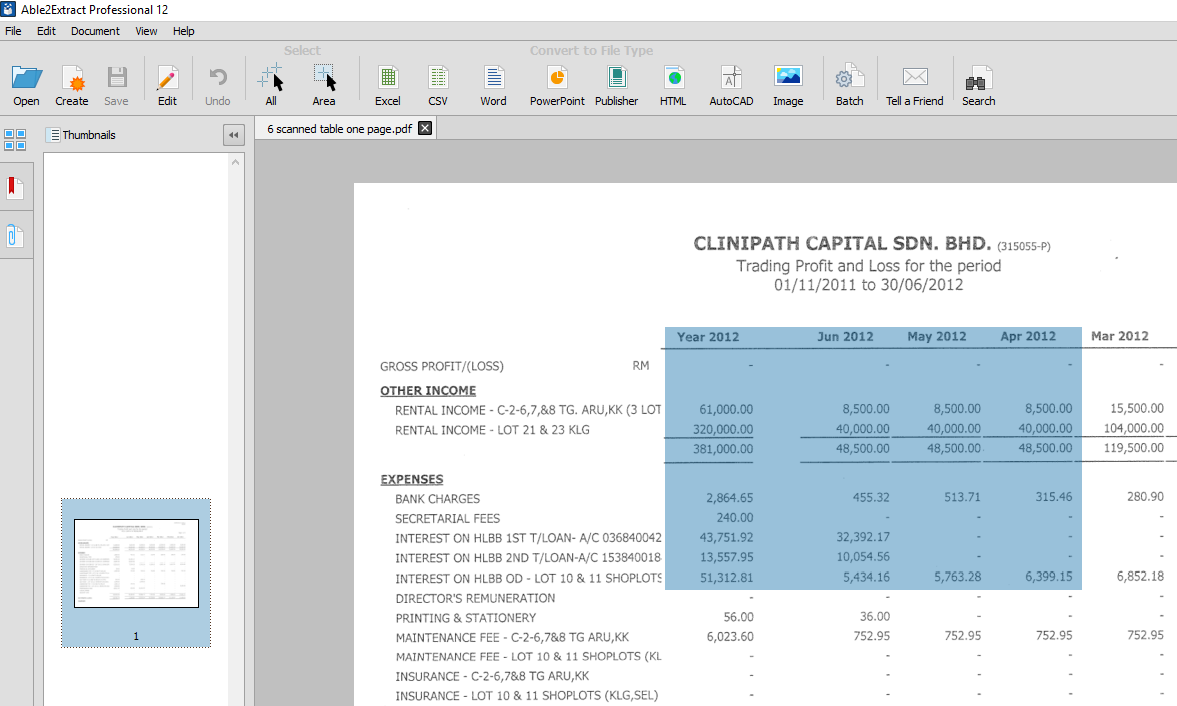
On the other hand, if only the text is highlighted – line by line, while the area in between is not highlighted – the document is a native (electronic) and you do not need the OCR to convert it.
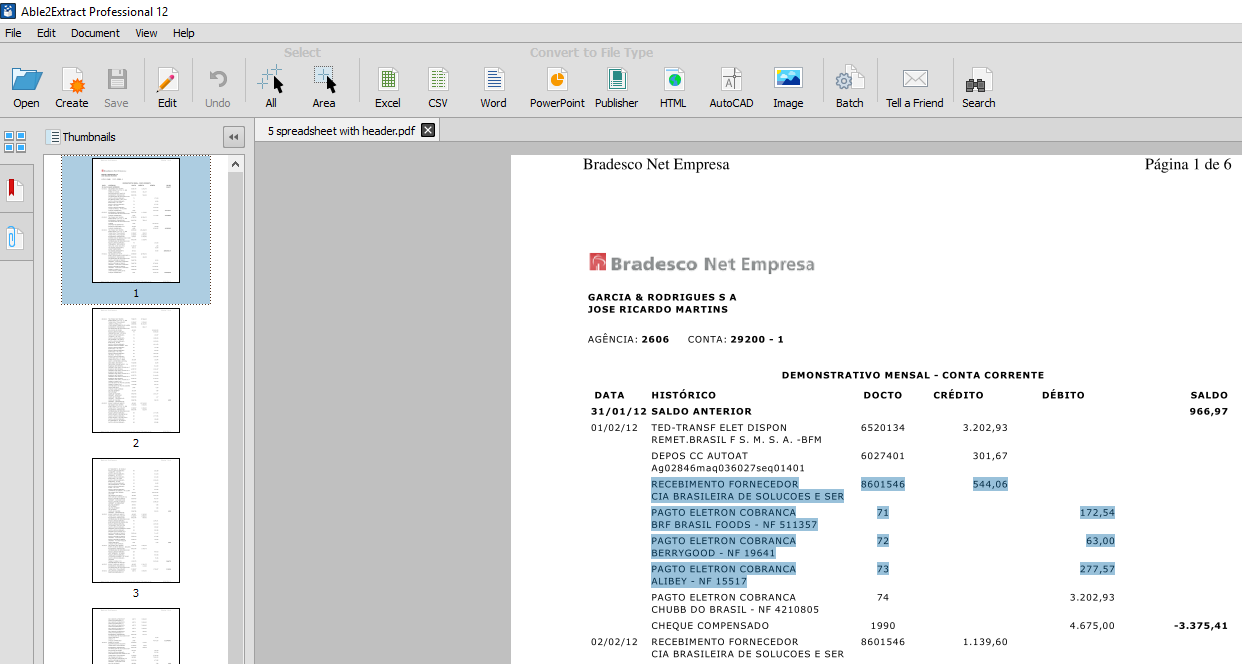
This article refers to Able2Extract and Able2Extract Professional.
Comments